

PRAGMA solves half the problem
Revolut’s new foundation model shows where behavioral AI works and where it structurally cannot. Reading it carefully tells you exactly what has to be built above it.

Revolut published PRAGMA last week. It is the most consequential financial AI paper of the year, and the people who matter in European finance have read it twice. They should.
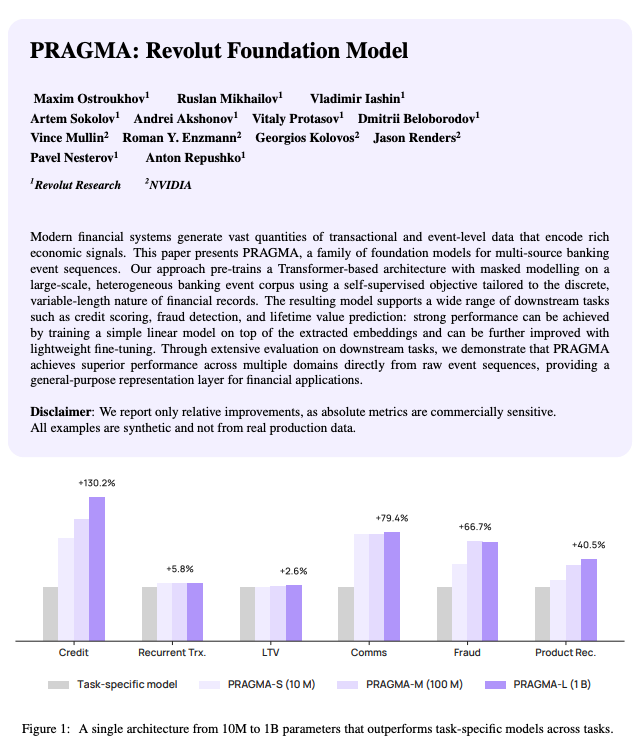
The paper describes a family of Transformer encoder foundation models — 10M, 100M, and 1B parameters — pre-trained on 207 billion tokens drawn from 24 billion banking events across 26 million users in 111 countries. The architecture is a three-stage encoder: a profile-state encoder handling contextual attributes, an event encoder processing individual events independently, and a history encoder fusing both into a single user-level embedding. Masked self-supervised pre-training. Thin task heads on top — linear probes, or LoRA fine-tuning on 2–4% of parameters. One backbone, many tasks.
The headline numbers are strong. The paper reports, as relative lifts over Revolut’s own task-specific production baselines:
Credit scoring: +130.2% PR-AUC, +12.4% ROC-AUC
Communication engagement: +79.4% PR-AUC, +20.4% ROC-AUC
External fraud: +64.7% recall, +16.7% precision
Product recommendation: +40.5% mAP
Lifetime value: +1.8% PR-AUC
Recurrent transactions: +5.8% F₁
These are not minor tuning gains. They are the lift you see when a structural constraint has been removed from a mature discipline. The constraint Revolut removed: one model per problem. Separate models for fraud, credit, churn, recommendations — each with its own feature pipeline, each team starting from zero. That paradigm is now obsolete for any institution with the data scale and infrastructure to train a backbone.
But PRAGMA also reports a result that, in my reading, is more consequential than any of the positive numbers. On anti-money laundering, the paper states:
“PRAGMA suffers a 47.1% drop in F₀.₅ compared to the network-aware baseline, demonstrating that isolated record-level representations may be insufficient for this highly relational domain.”
Same architecture. Same data. Same training regime. Opposite result.
Revolut’s explanation is careful and correct: AML is inherently relational, and PRAGMA processes event histories in isolation. The paper identifies extending the model to capture cross-record interactions — a graph-neural-network layer on top of the embedding — as a promising direction for future work. Pavel Nesterov’s LinkedIn confirms Revolut is hiring for exactly this. They see the gap, and they have the right representation-level plan for closing it.
Here is what I want to argue, and what I think the paper implicitly confirms without quite saying out loud: the AML result is not just a relational-structure problem that graphs will solve. It is a structural prediction about the limits of any representation model, and it points to a different gap — one that graphs will not close, because graphs sit at the same layer as PRAGMA. The layer that will close it is somewhere else entirely.
This is the argument.
Seven questions, and why the types matter
I am going to work through seven questions about what PRAGMA does and does not do. Each is tagged with its type from the KROG competency-question taxonomy, because the type of a question determines what a system must contain to answer it. A predictive question and a deontic question have different answer shapes. PRAGMA is architecturally right for some and architecturally wrong for others. Making the boundary visible is the whole point.
1. What does PRAGMA produce? (attribute)
Dense user-level embeddings. Frozen, reusable, small enough to serve at inference scale. Downstream tasks sit on top as thin heads.
What a PRAGMA embedding is not: a proposition, a claim, a rule, or a decision. It has no truth value. It cannot be right or wrong in a legal sense. It can only be more or less useful when a task head reads from it. That distinction is what everything below turns on.
2. Which tasks transfer well, and which do not? (typed instance filter)
The paper’s results divide into three bands, and each band is structurally informative.
Large lifts (>50%): credit scoring (+130.2% PR-AUC), communication engagement (+79.4%), fraud recall (+64.7%). All predictive tasks. All about extracting behavioral signal from longitudinal history. Ground truth is latent but realized — the customer either defaults or doesn’t, opens the email or doesn’t, commits fraud or doesn’t. The model’s job is to find the pattern.
Moderate lifts (5–50%): product recommendation (+40.5% mAP), recurrent transactions (+5.8% F₁), lifetime value (+1.8% PR-AUC). Still predictive, but the task-specific baselines were already decent. The backbone helps; it doesn’t transform.
Large degradations: anti-money laundering (-47.1% F₀.₅). And this is not in the same category as the others. The question AML poses is not “how likely is this customer to do X?” It is: does this pattern, under a specific regulatory definition of a specific prohibited act, cross a specific threshold defined by a specific rule? Ground truth is not latent. It is constituted by the rule itself.
Revolut attributes the gap to missing cross-record relational structure, and they are right about the mechanism. Graphs will help. But even with a perfect graph layer added, AML remains categorically different from credit scoring. Credit scoring asks about a latent future behavior. AML asks about membership in a legally defined category. A richer representation — with or without graph structure — learns patterns. It does not learn rules. Rules are a different kind of object.
A representation model learns what is. It cannot learn what must not be, because “must not be” is not a fact about distributions. It is a fact about rules.
3. How does PRAGMA deliver its credit-scoring lift? (manner)
The mechanism is masked self-supervision over heterogeneous event tokens. The model learns the statistical regularities of customer behavior at the resolution of individual events and their temporal arrangement. A sequence of small grocery transactions followed by a rent payment followed by a salary deposit looks like one kind of customer. A sequence of round-amount international transfers followed by rapid withdrawals looks like another. Representation-space distances between customer clusters predict things task heads care about.
None of this involves rules. The representation is inductive — emerging from data, shaped by loss. The decision rule comes later, at the task head, typically linear. A linear head over a rich embedding is interpretable in one specific sense: you can read off which embedding dimensions contributed most to the decision.
It is not interpretable in the sense the European regulatory environment requires from August 2026 onward: you can explain why this customer was rejected in a sentence a regulator and a rejected applicant will accept.
The difference between weak and strong interpretability is the difference between research-publishable and production-deployable.
4. Can PRAGMA’s output serve as the basis for an adverse-decision notice? (deontic, modal yes/no)
Here the question type changes, and with it what the system must contain to answer.
GDPR Article 22, the EU AI Act from August 2026, and a growing body of credit-scoring jurisprudence all require that automated decisions with significant effects on an individual must be accompanied by the principal reasons for the decision, in a form the affected party can understand and contest. The US Equal Credit Opportunity Act and Regulation B impose the equivalent for credit.
“Your embedding was far from the embeddings of accepted customers” is not such a reason. “Your debt-to-income ratio exceeds our threshold of 40%, and that threshold is set by policy BR-047 derived from Basel IV Article N” is.
PRAGMA produces the first kind of output. The +130.2% credit-scoring lift means the model is very good at identifying who is likely to default. It does not mean the model can produce why in a form a regulator accepts. This is not a PRAGMA failure — it is the correct behavior of a representation model whose entire purpose is compressing a high-dimensional history into a usable vector. Compression is the opposite of explanation, mathematically.
PRAGMA’s output cannot alone serve as the basis for an adverse-decision notice under EU law. It can serve as an input to a decision that is then justified by a separate rule-layer system exposing the rule that was applied and the facts matched against it. The distinction is architectural, not cosmetic. Any bank that deploys PRAGMA into credit decisioning without the rule layer above it is taking a bet the regulators of 2027 will make cost money.
5. Must a PRAGMA-driven decision be justifiable to a regulator? (deontic)
Yes, with increasing specificity and shrinking latitude.
The AI Act designates credit scoring and insurance pricing as high-risk AI systems. From August 2026 this triggers deployer designation, technical documentation, logging, risk management, human oversight, transparency. None of these can be satisfied by the representation layer alone. All require infrastructure sitting around the model: identity credentials for the deployer, auditable decision records for each invocation, human-oversight workflows for high-stakes categories, risk ledgers for drift and degradation.
The regulator’s concern is not that PRAGMA makes bad decisions. It is that PRAGMA makes decisions whose basis cannot be interrogated by the affected party or the supervisory authority. That concern does not go away because the model is accurate. It intensifies because the model is accurate and opaque simultaneously.
For anyone actually building on PRAGMA: the model is one component of roughly seven that have to work together for a legally deployable credit decisioning system in the European market. Getting the other six right is where the competitive differentiation for the next three years will happen. PRAGMA itself will be reproduced — Stripe, Mastercard, and Visa have already announced their own foundation models, and tier-one banks with sufficient data scale will close the gap fast. What will not be reproduced fast is the governance layer above it.
6. Who is accountable when a PRAGMA embedding drives a rejection? (human entity)
This is the question that breaks every representation-only architecture, because it presupposes something a representation model cannot provide: a named agent with verifiable accountability for the decision.
The natural tendency is to answer “the model decided.” This is wrong legally and wrong structurally. A model has no legal personality. The accountable party is still a natural or legal person somewhere in the chain. The operational question is whether the system records which person, under which authority, with which supporting evidence, knowing what at the time of the decision, with what formally declared unknown.
That last field — what was formally declared unknown — is the one most production systems lack and the one with the highest legal consequence. A decision-maker who formally declared, at the time of the decision, that certain facts were unknown is protected against later negligence claims for those facts. A decision-maker whose knowledge state at the time was never recorded is not. This is the field that, more than any other, determines whether a decision stands up in a regulator’s review in 2028.
At minimum, a decision-capture record requires: actor DID (cryptographically verifiable identifier), actor credential (verifiable claim that this actor held this role at this time), action type, knowledge-state inputs, knowledge-state unknowns, authorization, delegation credential, alternatives considered, timestamp qualified under ETSI EN 319 421, signature in QES form under ETSI AdES, trigger, outcome, goal served, purpose invoked.
PRAGMA does not provide any of these. It is not PRAGMA’s job to provide them. They belong in a different layer, at a different level of the stack, doing different work.
This is also where the European regulatory environment becomes an architectural moat rather than a tax. American and Chinese competitors can build excellent representation models. They cannot yet build the decision-capture infrastructure that EUDI Wallet, eIDAS 2, and the AI Act together specify, because that infrastructure is specifically European. The institutions that build this layer well in 2026 will have a defensible position for a decade.
7. What cannot PRAGMA do, and what must be built above it? (concept)
PRAGMA cannot do five things, and each corresponds to a specific layer that has to exist independently.
It cannot express a rule. An embedding is not a proposition. A representation cannot say “customers with debt-to-income above 40% are ineligible for unsecured credit above €10,000 under our current credit policy, derived from Basel IV Article N.” That belongs in a rule layer — deontic specifications in controlled natural language, machine-evaluable at decision time, traceable to the regulatory or policy source.
It cannot justify a decision. Justification is a proposition-to-proposition mapping: given these facts, under this rule, the decision follows. An embedding can make decisions more accurate on average. It cannot supply the justification chain.
It cannot detect normative conflict. When two rules collide — GDPR Article 17 right-to-erasure against another law that has a five-year retention of suspicious-transaction records, as the canonical example — a representation model has nothing to say about the conflict because it does not represent either rule. A conflict-detection layer requires rules as first-class objects whose logical content can be compared.
It cannot record what was not known. The most legally significant field in a decision-capture record is what the decision-maker formally declared they did not know at the time. A representation model, by design, compresses away the distinction between “not in training data” and “formally declared unknown at decision time.” These are legally different states. Only an explicit decision-capture layer can distinguish them.
It cannot carry authority. A credential — a verifiable claim that an actor held a role at a time, issued by an authority, verifiable without reference to the issuer — is cryptographic infrastructure, not learned representation. The identity layer underneath every legitimate decision is verifiable credentials under EUDI ARF, W3C VC, sectoral trust frameworks. PRAGMA has no concept of a credential, and it would be wrong to expect one.
The pattern is unambiguous. PRAGMA is a substrate. The rule layer, decision-capture layer, conflict-detection layer, knowledge-state layer, credential layer — these sit above the substrate doing orthogonal work. A PRAGMA embedding is read by a rule-evaluator to produce a decision record signed by a credentialed actor whose authority chain is verifiable. The two architectures are not in competition. They are complementary, and both are necessary.
And this is the point that the future-work graph-encoder extension will not change. Adding a graph neural network on top of PRAGMA addresses the relational gap — cross-record network structure for AML, sanctions, synthetic-identity detection. It does not address the deontic gap — rules, justifications, accountability, credentials, declared unknowns. The relational gap sits inside the representation layer. The deontic gap sits outside it entirely.
What this adds to the PRAGMA reading
Three things.
First: the AML degradation is not simply a relational-structure problem. It is also a predictor that any rule-constituted task will be hard for a representation model, with or without graph augmentation. The category is larger than AML — it includes sanctions screening, consent validation, high-risk third-country transfers, SAR trigger logic, internal policy violations. These are not future work. They are the current compliance workload of every European bank.
Second: the architectural lesson for anyone reading PRAGMA is not “build a bigger model.” It is “build the deontic layer above the model, in parallel with the model itself.” Institutions that build both simultaneously will ship deployable systems in 2026. Institutions that build only the representation layer will spend 2027 retrofitting the governance layer under regulatory pressure. That is a worse path, operationally and competitively.
Third: the foundation-model race is nearly decided at the representation layer. Within two years, every tier-one financial institution will have built or acquired a PRAGMA-equivalent backbone. The distinctive competitive advantage from the model layer alone is measurable in quarters, not years. The distinctive advantage from the governance layer is measurable in a decade, because the regulation that mandates it is jurisdiction-specific, the identity infrastructure that satisfies it is jurisdiction-specific, and the formal apparatus that makes it operable — KROG’s deontic logic and jural correlatives, controlled natural language, the decision-capture schema — is specific to a small number of people who have spent the years required to work with it fluently.
The prescription
PRAGMA is the first half of a two-half problem. The half it solves is extraordinary: one backbone, six tasks, superhuman lifts on the tasks that have the right shape. The half it does not solve is the half that makes the first half legally deployable in Europe from August 2026 onward.
That second half has a known architecture. At the bottom, an append-only knowledge graph making every event queryable with cryptographic integrity. Above it, a layer with machine-evaluable obligations enabled by KROG. Above that, a rule layer expressing deontic specifications in logical form enabled by KROG. A conflict register detecting contradictions between rules. A credential and actor-registry layer carrying verifiable claims about who is authorized for what. A gateway evaluating every agent action against the rule set before execution. A human-decision layer capturing qualified signatures, delegation chains, and formally declared unknowns. A KPI and workflow layer tracking obligations against deadlines. A legal-basis layer grounding every processing activity. A strategy layer recording the institution’s declared intent. And an ecosystem layer tracking changes in external regulatory instruments so the whole stack updates when the law does.
Fourteen layers. Each answers a distinct question no other layer can answer. Each is a first-class component, not a feature of another component. This is the architecture I build and ship.
If you are Revolut, you have the representation layer. The question is whether the stack above it is being designed to the same standard of formal rigor — whether every FinCrime agent action is gated against explicit rules, whether every decision carries a knowledge-state and an authorization credential, whether the whole is queryable as a single graph rather than a collection of logs. If yes, there is an obvious commercial opportunity in productizing that governance stack for the banks that want PRAGMA-equivalent capability without your data scale. If not, this is the architecture to build next.
If you are SEB, Handelsbanken, DNB, Nordea, or any other European bank reading PRAGMA and wondering how to respond — the answer is not to build PRAGMA. It is to build the deontic layer first, prove it operationally, then acquire or build the representation layer on top once the governance substrate is in place. That order of operations suits a bank with a real compliance function, deep customer relationships, and regulatory obligations under seventeen frameworks already being managed by hand. The single concrete scenario I use to make this tangible: when the ECB or your national regulator asks “show us every AI-generated decision in the past year where human oversight was absent or overridden, with the full reasoning chain for each” — you either run a query and answer in hours, or you spend three months assembling evidence from disconnected systems. The architecture above makes the first possible. Nothing any bank currently has does.
Either way, the relevant question is not whether this layer needs to exist. The AI Act settles that by August. The relevant question is who builds it — and whether the institution builds it deliberately now or reconstructs it reactively in 2027.
I would like to have that conversation.
Paper: Ostroukhov et al., “PRAGMA: Revolut Foundation Model,” arXiv:2604.08649, April 2026. All performance figures in this piece are drawn directly from the paper’s own tables, including the -47.1% F₀.₅ AML result in Section 3.4.5. Complete rule logic by KROG.